Avoiding the Frankenstein prompt
It’s not hard to write a pretty good prompt. There are plenty of great guides and documentation. However, crafting one that’s robust enough for production can be challenging.
One common trap I’ve fallen into is what I call the Frankenstein Prompt. It essentially goes like this:
You create a POC which receives positive feedback. The stakeholders are enthusiastic and ready to advance. The POC is powered by “good enough” prompts that work well in the demo but start failing during more rigorous UAT and evals.
As edge cases and exceptions emerge, you start haphazardly adding to the prompts, trying to patch the holes. You find yourself in a game of whack-a-mole, where fixing one issue causes previously working parts to break. The more you try to address individual problems, the more fragile the prompts become.
Before you know it, your prompts have turned into a Frankenstein’s monster - a large, brittle chimera that’s difficult to manage and maintain. Each iteration adds more complexity and confusion, making it harder to understand and modify the prompts.
Finally, after countless frustrating debugging sessions, you take a step back and reassess the situation. With a zoomed-out perspective, you finally understand what the customer needs and how the model should behave across every scenario. You realize that the best course of action is to kill the Frankenstein prompt and start from scratch.
Armed with your newfound clarity, you sit down and rewrite the prompts from the ground up. This time, the logic is clean and clear. The resulting prompts are easier to understand and maintain. They’re robust, passing your evals. Now they’re ready for production.
The purpose of this post is to capture my current best practices for prompt generation and evaluation, specifically for Anthropic’s Claude 3. In it, we’ll cover:
- Questionaires for guiding prompt creation
- System prompts
- Task-specific prompts
- Visual document understanding prompts
- Evaluation
1. Questionnaires
To avoid falling into the Frankenstein Prompt trap, it’s crucial to invest time upfront in understanding the problem, requirements, and expected behaviors. This is where questionnaires come in. They help you gather and organize the necessary information to create robust, production-ready prompts.
I created two questionnaires (see Appendix) to aid in this process: a system-level questionnaire and a task-level questionnaire. The system-level questionnaire focuses on the big picture, capturing the overall problem, end-to-end process, and tasks the model will assist with. The task-level questionnaire dives into the specifics of each task, covering aspects like task description, input data, outputs, definitions, heuristics, instructions, edge cases, examples, and evaluation criteria.
By completing these questionnaires, you create detailed artifacts akin to requirements documents or PRFAQs. These can then serve as robust foundations for generating precise and effective prompts, whether done manually or using tools like metaprompt.
This approach doesn’t eliminate the need for testing and iteration, but it does make the process more efficient. By having a clearer understanding of the requirements from the start, you can reduce the number of iterations required and save yourself from a lot of headaches!
2. System Prompts
My system prompt typically has six parts:
- Persona - who are you and what are you good at
- world’s finest AI assistant at X, with deep expertise in X, Y, Z
- Role - what are you helping humans do
- You help X do
- Big Picture - what is the big thing we’re trying to solve
- At a high-level, the end-to-end process goes as following…
- Overview of specific tasks - what will you specifically be responsible for
- You are responsible for these specific tasks…
- General behavior - guidance on what should you do all the time
- You always take your time, think step-by-step, and pay extreme attention to detail…
- Format guidance - what should the expected output of the prompts be
- XML vs JSON
The big picture is helpful because often times you’re running LLM calls in parallel or they’re working on a task in a greater chain of tasks without that knowledge. The system prompt can help “pull” all these calls in the same direction.
3. Task-Specific Prompts
I typically follow this format, with a specific tag in thinking tied to each step:
Please carefully read the following:
<context_description>
</context_description>
...
</context_description>
</context_description>
<instructions>
1. Do X
2. Do Y
3. Do Z
4. Carefully think step-by-step and take your time to return an answer in this format:
<thinking>
<some_tag>output of step 1</some_tag>
<some_other_tag>output of step 2</some_other_tag>
<another_tag>output of step 3</another_tag>
</thinking>
<answer>
<tag_to_parse>output description</tag_to_parse>
<tag_to_parse>output description </tag_to_parse>
</answer>
</instructions>
I’ve found that explicitly creating XML tags within thinking for each step improves model adherence to instructions.
Previously, I used a different instructions flow where I’d list several steps then tell the model to do those within <thinking>.:
<instructions>
1. Do X
2. Do Y
3. Do Z
4. Carefully think step-by-step and perform steps 1, 2, 3, writing your notes and thinking process within <thinking></thinking> tags.
5. Once you have completed the above, return your final answer in the format below.
<answer>
<tag_to_parse>output description</tag_to_parse>
<tag_to_parse>output description </tag_to_parse>
</answer>
</instructions>
The problem here is that the model could be inconsistent in carrying out all steps in thinking, sometimes executing all steps and other times only executing a few.
Decision Trees
For more complicated instructions with if-else statements, special definitions, and exceptions, I’ve found that creating a decision tree using a mermaid diagram and adding it to the instructions helps. The questionnaire is useful for this. You can pass the same artifact to an LLM to create a mermaid diagram and iterate on it to ensure accuracy. The mermaid diagram also becomes a useful visualization to share with your customers.
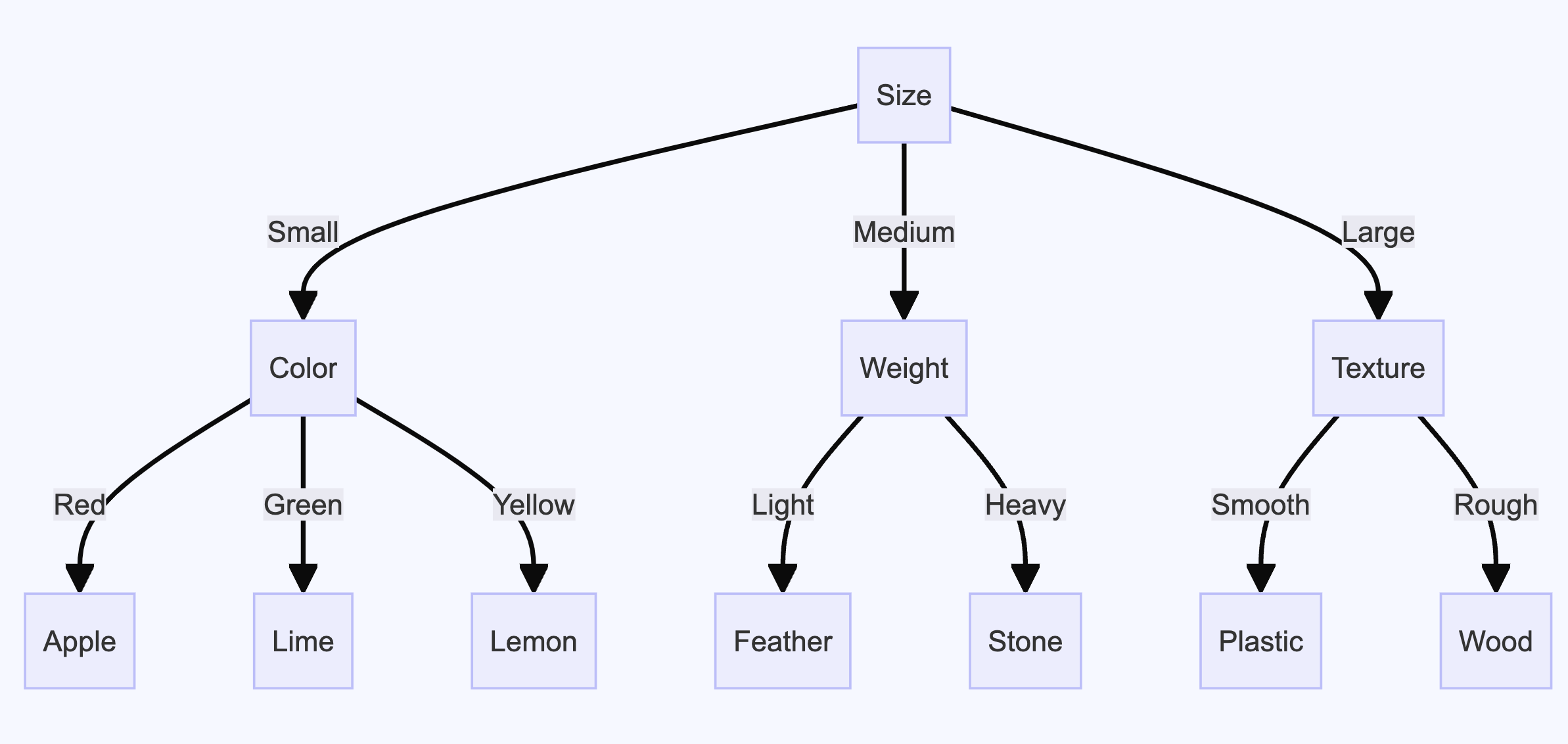
graph TD
A[Size] -->|Small| B[Color]
A -->|Medium| C[Weight]
A -->|Large| D[Texture]
B -->|Red| E[Apple]
B -->|Green| F[Lime]
B -->|Yellow| G[Lemon]
C -->|Light| H[Feather]
C -->|Heavy| I[Stone]
D -->|Smooth| J[Plastic]
D -->|Rough| K[Wood]
E[Apple]
F[Lime]
G[Lemon]
H[Feather]
I[Stone]
J[Plastic]
K[Wood]
The main idea is that creating a decision tree forces you to define expected behavior and identify edge cases in the prompt, helping the model follow the correct process.
Overall, marrying a specific tag in thinking to each step and defining decision trees in your prompt via mermaid diagrams improves instruction following and leads to more consistent outputs.
4. Vision Prompts
You can use Claude for document understanding tasks. As someone who used to do a lot of Textract and LayoutLM fine-tuning, I find this extremely useful, especially for “complicated” tables. For example, consider this electric summary sheet from Puget Sound Energy, which shows rate schedules. Based on attributes such as lamp type (High Pressure Sodium Vapor or LED), wattage, effective date, and bill components, we might want to parse a specific value.
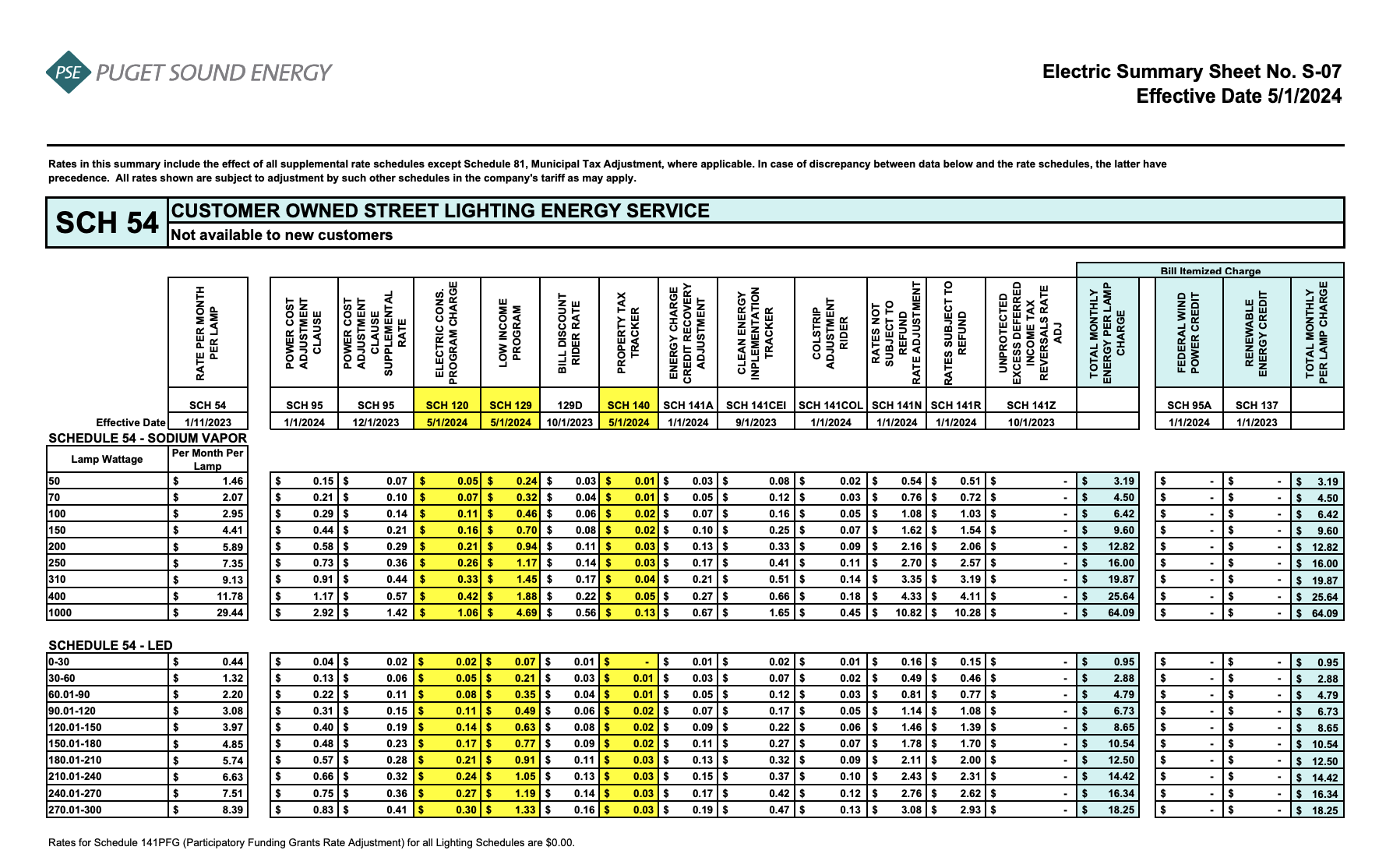
While simple for a human, traditional methods like Textract would struggle with this table due to factors like multi-level headers and shared columns between sub-tables. Fortunately, Claude’s vision capabilities perform better in these scenarios.
For simple document understanding tasks, you can write straightforward queries like “What is …?”. However, for more complex tables like the one above, I have found the following approach helpful:
- Have a powerful model like Sonnet or Opus generate a rich description and visual representation of the table and add that to the prompt.
- Write step-by-step instructions similar to the previous sections. One of the steps should ask the model to visualize and recreate the specific section of the document they should extract from.
- Have a powerful model like Sonnet or Opus create few-shot examples based on the instructions.
Once your prompt is written, you can execute it using Claude Haiku, saving you time and money. Here’s what a prompt for parsing the above image might look like:
<document_description>
The image shows an Electric Summary Sheet from Puget Sound Energy effective 5/1/2024. It contains detailed rate schedules for customer-owned street lighting energy service (SCH 54) that is not available to new customers.
Table layout:
- The main table has rows labeled with lamp wattages (e.g., 50, 70, 100) and columns representing bill components for different effective dates.
- The bill components include Energy Charge, Power Cost Adjustment, Low Income Program, and more. Each component has subcolumns for cents per kWh and dollar amounts.
- The cells contain the charge amounts in dollars or cents per kWh for each combination of lamp wattage, bill component, and effective date.
- Below the main table is a second table labeled "SCHEDULE 54
- LED" which shows rates for LED street lighting. It has a similar structure but the rows are for different LED wattage ranges.
</document_description>
<visual_representation>
CUSTOMER OWNED STREET LIGHTING ENERGY SERVICE
Lamp Wattage SCH 54 SCH 95 SCH 120 SCH 129 129D SCH 140 SCH 141A SCH 141COL SCH 141N SCH 141R SCH 141Z SCH 142 SCH 99A SCH 137
50 X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX
70 X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX ...
SCHEDULE 54 - LED
LED Wattage SCH 54 SCH 95 SCH 120 SCH 129 129D SCH 140 SCH 141A SCH 141COL SCH 141N SCH 141R SCH 141Z SCH 142 SCH 99A SCH 137
0-30 X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX 30.01-60 X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX X.XX
...
</visual_representation>
The tables provide charge amounts based on the following attributes:
- Lamp Type: The type of lamp (e.g., High Pressure Sodium Vapor or LED).
- Wattage: The wattage of the lamp. For High Pressure Sodium Vapor, it's a specific value (e.g., 50, 100, 250). For LED, it's a wattage range (e.g., 0-30, 90.01-120).
- Bill Component: The specific component of the bill (e.g., Energy Charge, Low Income Program Charge).
- Effective Date: The date the rates are effective from (e.g., SCH 54 1/1/2023, SCH 95 5/1/2023, SCH 129 1/1/2024).
</document_description>
<instructions>
</instructions>
<example name='example1'>
<attributes>example attr</attributes>
<output>example thinking + answer </output>
</example>
<example name='example2'>
<attributes>example attr</attributes>
<output>example thinking + answer </output>
</example>
Your goal is to X based on the following attributes:
<attributes>
</attributes>
5. Evaluation
Evaluating LLM outputs can be difficult and is currently more art than science, relying partially on subjective customer feedback and the eye test. PromptFoo is a useful tool for generating test cases and comparing prompts head-to-head in a more programmatic way.
PromptFoo uses a YAML configuration:
prompts:
- file://prompts/some_prompt.txt
providers:
- 'exec: python scripts/claude_v3.py'
defaultTest:
assert:
- type: python
value: file://scripts/is_valid_xml.py
- type: python
value: file://scripts/check_classification.py
tests:
- vars:
prompt_var: file://context/some_context.md
prompt_var2: file://context/other_context.md
for_ui: "easy for you to read"
expected_answer: "some answer"
promptspoints to a .txt file containing the prompts to test, separated by---.providerspoints to a Python file defining the model and its parameters.defaultTestallows you to apply tests to all examples using custom Python scripts.
Custom test scripts typically follow this format:
if __name__ == "__main__":
output = sys.argv[1] # this is LLM output
inputs = sys.argv[2] # formatted prompt + input vars from yaml
# do something
response = {
"pass": some_condition,
"score": some_score,
"reason": additional_information
}
print(json.dumps(response))
Through these scripts, you can run tests like:
- ensuring proper XML or JSON formatting
- measuring classification accuracy
- searching for hallucinations
For example, you could parse citations from the LLM output (argv[1]) then check if they’re grounded in the context originally shared with the model (argv[2]).
While I focus purely on programmatic evals, PromptFoo also supports LLM-as-evaluator evals. I don’t think PromptFoo supports image evals yet, so for document understanding tasks I’ve relied on custom tests. If you’ve figured that out, let me know.
6. Conclusion
Prompting opens up a lot of possibilities! By applying the techniques covered in this post, such as using questionnaires, structuring prompts thoughtfully, and incorporating decision trees and custom evaluation methods, you can create more reliable and consistent production-ready prompts for Generative AI solutions.
Perhaps these all become obsolete with Claude 3.x but until then, happy prompting!
Appendix
Questionaire
System Prompt Questionaire
- What is the overall problem you’re trying to solve?
- What is the end-to-end process look like?
- What are the tasks within the process that you want the model to help with?
Task-Level Questionaire
- Task Description
- What is the main task or goal you want the model to accomplish?
- A clear and concise description of the task
- Input Data
- How many inputs?
- Brief description of each input
- How should they be used?
- Outputs
- What is the desired format, XML vs JSON?
- What are the output fields?
- Definitions
- Define any key terms or definitions
- Define any acronyms that may be passed in as context
- Heuristic
- Working backwards, what are the steps to derive the correct answer(s)?
- What does a human do today (if addressing existing workflow)?
- Convert this heuristic into high-level step-by-step instructions
- Instructions
- For each step, what should the model do?
- Ambiguity and Edge Cases
- Are there if-else flows?
- What are potential edge cases?
- Are there ambiguous steps that the model can interpret differently run-to-run?
- Few-shot Examples
- Do you have examples of input-output pairs (even if you don’t have the intermediate thinking steps)?
- DOs and DONTs
- Is there behavior you want the model to definitely do?
- Is there behavior you want the model to avoid?
- Evaluation
- Can the output(s) be graded in a supervised or binary fashion?
- If not, what criteria can be used to evaluate the quality?
- Is there a direction you want to steer it in?
- for example - if you extracting citations, a FN (missing something important) might be really bad so you might say its better to overcite
Prompting Gotchas
Order Matters
Consider these two different instructions.
- Classify x into a, b, or c. Think step-by-step and explain your reason.
- Your task will be to classify x into a, b, or c. Before choosing a classification, think step-by-step to…
In the first prompt, the model might classify (sometimes incorrectly) and then justify its answer. In the second prompt, the model will think first, then classify.
The order in which you present instructions to the model can significantly impact the output quality and accuracy. Always consider the optimal sequence of steps to guide the model towards the desired outcome.
Related Reading / Resources
- Everything I’ll forget about prompting LLMs - inspo
- Bedrock Claude 3 Deep Dive - slide deck with useful tips
- Anthropic Cookbook - code examples